Deep Learning (6) - 从GPT到ChatGPT
什么是fine-tune
fine-tune可以说是对原模型的参数进行“微调”。但微调的方法有很多种,比如:
- 直接在原网络上用新的数据训练
- 固定原网络的前面若干层的参数,训练后面几层的参数
- 搭建一个新的网络,以原模型的某一个layer的输出为输入,针对一个特定的任务,使用少量数据,固定原网络的参数,训练出新网络(相当于替换 原来网络的输出层)。
Reinforcement Learning
强化学习是一种与深度学习无关的机器学习方法。
强化学习不需要训练数据集,而是通过与环境交互来学习。在强化学习中,智能体(Agent)通过执行某些动作来影响环境,并从环境中获得奖励或 惩罚。智能体的目标是最大化长期累积奖励。
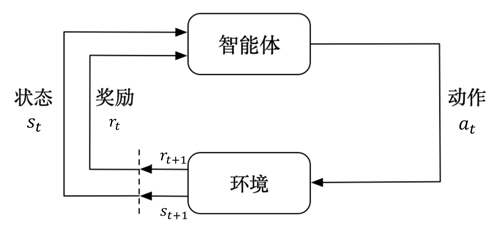
强化学习与深度学习可以结合,以深度学习的模型为Agent,通过强化学习的方法来进一步优化模型。
长期以来出于工程和算法原因,人们认为用强化学习训练大语言模型是不可能的。OpenAI提出的近端策略优化 (Proximal Policy Optimization, PPO)算法,可以有效微调初始语言模型的部分参数。因为微调整个 10B~100B+ 参数的成本过高。
InstructGPT
InstructGPT是在GPT-3(参数数量1750亿)上fine-tune出来的模型。训练过程使用了RLHF方法(reinforcement learning from human feedback)。

第一步:有监督微调(SFT)
有监督微调使用人工编写的数据集进行。数据有从用户通过API提交的prompt和人工编写的答案,也有完全由人工编写的prompt和答案。其中用户提交的数据约1500条,人工编写的数据约13000条。
第二步:奖励模型(RM)
奖励模型的输入是prompt和候选答案,输出是分数。
让GPT模型生成出一个prompt的多个候选答案,然后人工评估这些候选答案的质量,给出一个分数。用这个数据集训练奖励模型。
奖励模型的训练数据,也有用户提交的和人工编写的。用户提交的数据约4万条,人工编写的数据约1万条。参数数量是60亿。
第三步:强化学习微调(PPO)
第二步训练出来的奖励模型,作为强化学习的奖励函数。强化学习的目标是让模型生成的答案的分数尽可能高。这一步使用了4万7千条用户提交的数据。
通过这样的三个步骤,将人类的反馈和喜好,转化为了模型的参数,从而实现了模型的微调。从实际生成的数据看,GPT-3只会生成一些漫无目的的 内容,而InstructGPT生成的内容则更加有意义。其中的原因可能是GPT-3训练的数据集中,大部分都不是问题/答案的形式,而InstructGPT通过少量 数据集的微调,使得模型更倾向于生成问题的答案。

ChatGPT
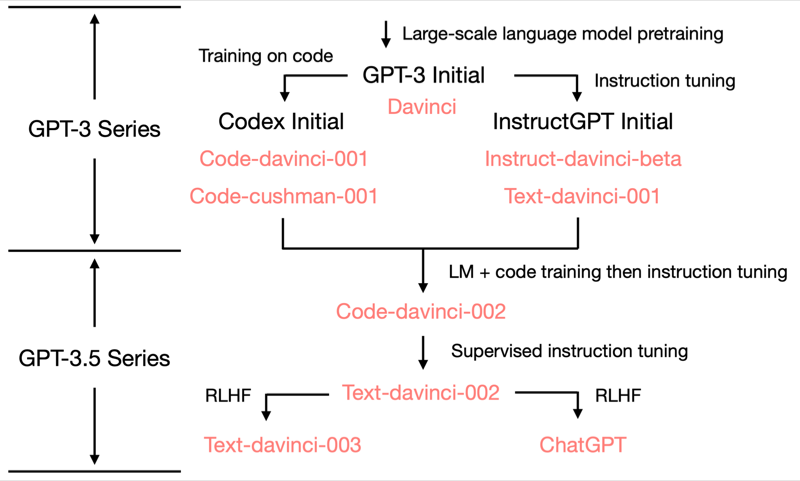
ChatGPT是基于InstructGPT进一步优化出来的模型,脉络如下:
参考
[1] https://mp.weixin.qq.com/s/TLQ3TdrB5gLb697AFmjEYQ
[2] https://cloud.tencent.com/developer/article/2216036
[3] https://blog.csdn.net/tMb8Z9Vdm66wH68VX1/article/details/128928143