Deep Learning(3) - 从Encoder-Decoder到Transformer
seq2seq问题
seq2seq用于将一个序列(sequence)转换成另一个序列,典型的场景是机器翻译,语音识别,给图片生成描述,问答,语音合成,代码生成等。
Encoder-Decoder
Encoder-Decoder架构是一种适用于seq2seq问题的模型。Encoder将可变长度的序列作为输入并将其转换为具有固定形状的状态,而Decoder则将该状态作为输入并生成输出序列.
在Encoder-Decoder架构中,Encoder和Decoder都是由RNN或LSTM组成的,但是它们的输入和输出都是不同的。Encoder的输入是一个序列,而Decoder的输入是一个向量,该向量是Encoder的输出。Encoder的输出是一个向量,该向量是Decoder的输入。Encoder和Decoder的输出都是向量,但是它们的长度可以不同。Encoder和Decoder的输出向量可以用于不同的任务,例如机器翻译,其中Encoder的输出向量可以用于生成翻译的源语言的表示,而Decoder的输出向量可以用于生成翻译的目标语言的表示.
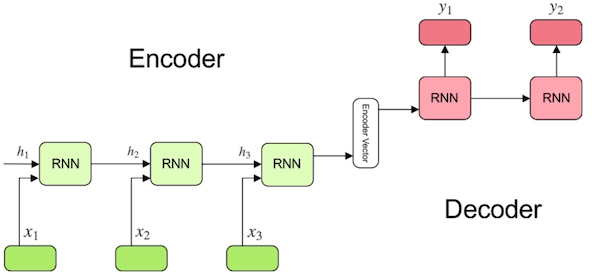
用Encoder-Decoder来翻译一段文字,其数据流程是这样的:
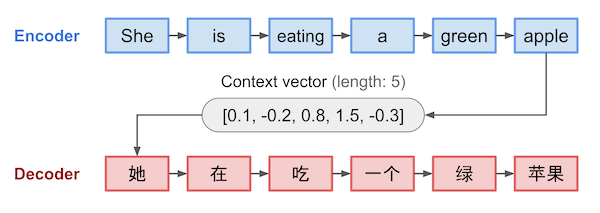
Encoder部分输入一段文字(She is eating a green apple),经过一个RNN或LSTM网络后,生成一个固定长度的向量,然后Decoder负责将这个向量生成对应的文字。
Attention机制
对于朴素的Encoder-Decoder架构,从一个固定的向量要生成各种文字,这样生成的文字与原文的对应关系肯定是比较差的。
我们可以让每一个生成的文字,与原文的对应文字有一定的对应关系,这就是注意力机制。
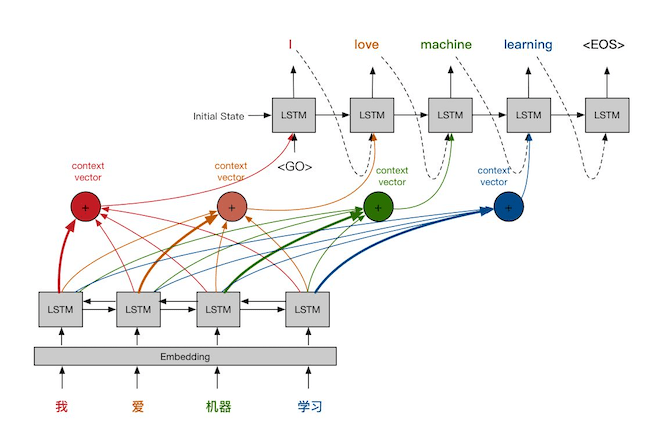
下图中,每一个生成的文字,不仅与整个Encoder的输出有关,还与每一个位置的输出都有关。这里产生了4个不同的Context Vector,每个Context Vector都主要与当前输入有关,但同时也与之前之后的词相关。可以认为,每个不同颜色的Context Vector,表达了对不同输入位置的注意力。
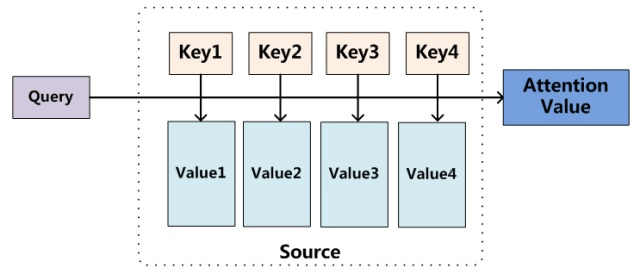
Attention本质上是一组参数,可以理解为Query, Key, Value的函数。输入源数据中的元素可以定义为<Key, Value>数据对,目标中的要生成的输
出元素为Query,那么最终生成的attention可以定义为:
由于Attention的计算并不需要一定的顺序,所以可以同时计算多个Attention:
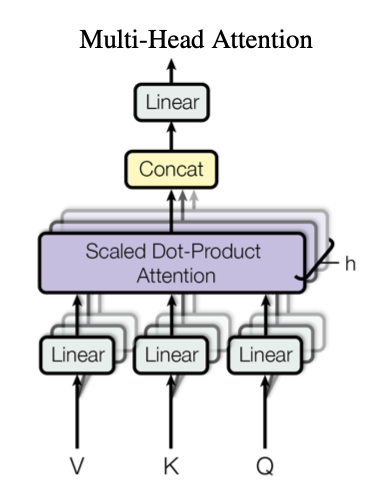
Multi-Head Attention是利用多个查询,来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接。
Transformer
Google在2017年发表了一篇论文Attention is All You Need。在Encoder/Decoder中取消了传统的RNN/LSTM单元,而是完全使用attention机制重新构建了encoder和decoder,取得了非常好的效果。
![]()
- Transformer中的编码器
- 编码器由N=6个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”,这里是6x个。每个Layer由两个子层(Sub-Layer)组成,第 一个子层是Multi-head Self-attention Mechanism,第二个子层比较简单,是Fully Connected Feed-Forward Network。
- 解码器
- 解码器同样由N=6个相同layer组成。解码器中对self-attention子层进行了修改,以防止引入当前时刻的后续时刻输入,这种屏蔽与输出嵌入偏 移一个位置的事实相结合,确保了位置i的预测仅依赖于小于i的位置处的已知输出。
参考
[1] https://imzhanghao.com/2021/09/15/self-attention-multi-head-attention/