Deep Learning (5) - BERT vs GPT
BERT和GPT都是基于transformer的预训练模型,但是它们的预训练任务不同。BERT的预训练任务主要是掩码语言模型(在一个句子中随机盖住一些词,让模型预测)和下一句预测,而GPT的预训练任务主要是语言模型(根据前面的词预测下一个词)。BERT在分类任务中表现良好,而GPT在生成任务中表现良好。BERT的优点是可以在小数据集上进行微调,而GPT的优点是可以生成连贯的文本。
BERT
BERT由Google在2018年提出。目标是:enables anyone to train their own state-of-the-art question answering system.
BERT最重要的技术突破是在预训练时使用了掩码语言模型和下一句预测。掩码语言模型是指在输入序列中随机掩盖一些单词,然后让模型预测这些 单词。下一句预测是指在输入序列中随机选择两个句子,然后让模型预测这两个句子是否相邻。这两种预训练任务都可以让模型学习到更好的语言 表示,从而提高模型在下游任务中的表现。
BERT在许多任务上表现出色,例如情感分析、问答、命名实体识别(NER)和下一句预测等。BERT已经被谷歌用于其搜索算法。
百度的ERINE(Bert and Erine是芝麻街中的两个角色,好朋友, they have long been gay icons)本质上也是一个BERT模型。
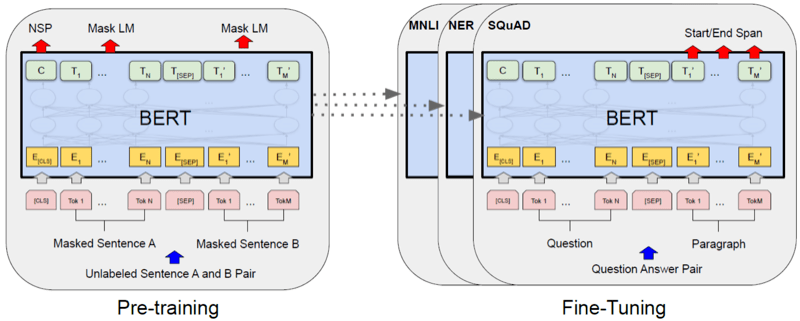
BERT整体框架包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练,fine-tune阶段,BERT模型首先是被pre-train模型参数初始化,然后所有的参数会用下游的有标注的数据进行训练。
BERT只使用了Transformer的encoder侧的网络,模型的输入会被转换768维度,然后分成12个head,每个head的维度是64维。
BERT模型分为24层和12层两种,其差别就是使用transformer encoder的层数的差异,BERT-base使用的是12层的Transformer Encoder结构,BERT-Large使用的是24层的Transformer Encoder结构。
预训练
BERT的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP。
MLM(Mask Language Model)
MLM是指在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。
MLM的这个性质和Transformer的结构是非常匹配的。在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂 到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
- 80%的时候会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。
- 10%的时候将其替换为其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。
- 10%的时候会保留原始Token,例如保持句子为 “my dog is cute” 不变。
NSP(Next Sentence Prediction)
NSP的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两 句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
在此后的研究(论文Crosslingual language model pretraining等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与 原始BERT持平或略有提高。这可能是由于Bert以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、 spanBERT都移去了NSP任务。
微调
微调实例上是指BERT训练后模型的应用过程,通过训练,在BERT模型中学习到了一些语言中的features,fine tuning过程是将这些feature应用到实际问题的过程。
这里的任务可以包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。
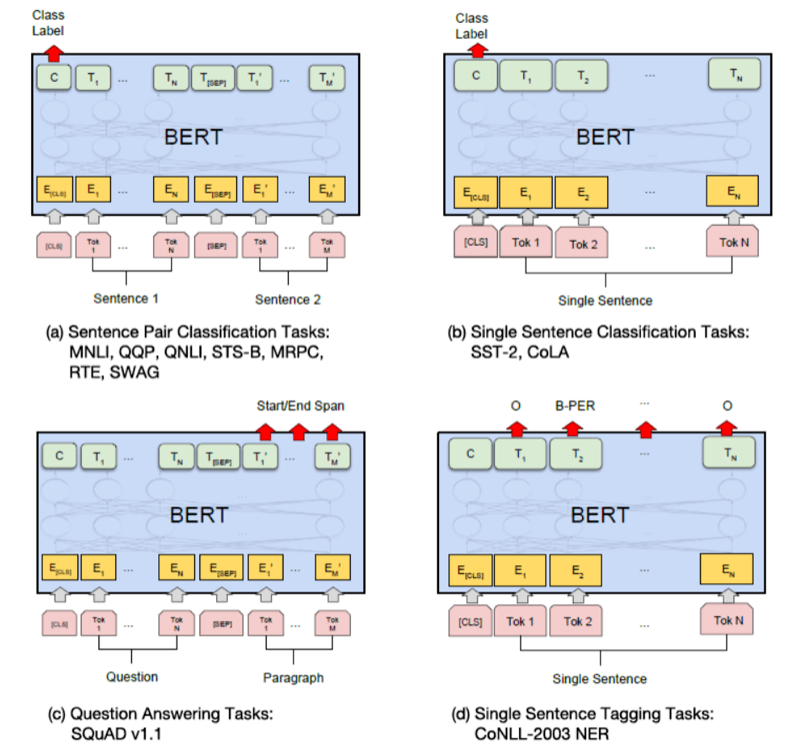
微调的过程,通常使用监督模型,通过选取BERT输出向量中的不同部分,后面连接一个全连接前向网络,再使用数据进行有监督训练。
GPT
GPT采用了与BERT整体类似的架构,也是pretrain + fine tuning,但有很多细节不同,最重要的不同是以下:
- GPT使用了Transformer中的Decoder部分,而不是Encoder部分
- GPT训练的目标与BERT有很大不同,其目标是使用句子序列预测下一个单词
例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D
可以看到,GPT的模型天生就是为生成文字设计的。BERT的语言模型,在训练时(MLM)就使用了单词之前和之后的信息,从而导致生成出来的模型,与之前之后的信息都有关。而GPT是单向的,只依赖之前的信息,不依赖之后的信息。
chatGPT是在GPT模型之上fine tuning的结果。理论上讲,用自己领域的文档和内容,去fine tuning GPT模型,有可能在这个领域内得到比chatGPT更好的结果。
参考
[1] https://jalammar.github.io/illustrated-bert/
[2] https://blog.csdn.net/Zhangbei_/article/details/85036948
[3] https://symbl.ai/blog/gpt-3-versus-bert-a-high-level-comparison/
[4] https://paddlepedia.readthedocs.io/en/latest/tutorials/pretrain_model/bert.html