Deep Learning (4) - Word Embedding
介绍
Word Embedding是NLP处理的第一步,要将一段文字送入模型,必须先将其转换成数字。Word Embedding将每个词转换成为一个向量。
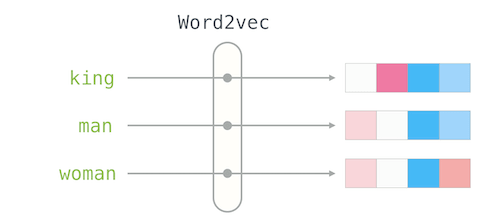
Word2vec
Word2vec是Word Embedding的方法之一。他是2013年由谷歌的Mikolov提出的。在此之前,并没有成熟的Word Embedding方法。
训练Word2vec有两种方法:skip-gram和CBOW。
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』
- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
模型训练时候的输入,是one-hot vector,也就是只有一个1,其余都是0的向量。如果所有输入的字词有n个,那这个向量的维度就有n,每一个词都 对应某个维度为1,其余维度为0的向量。
在训练的时候,对应的输出也是one-hot vector,最终模型训练完之后,我们需要的是中间层输出的一组权重。
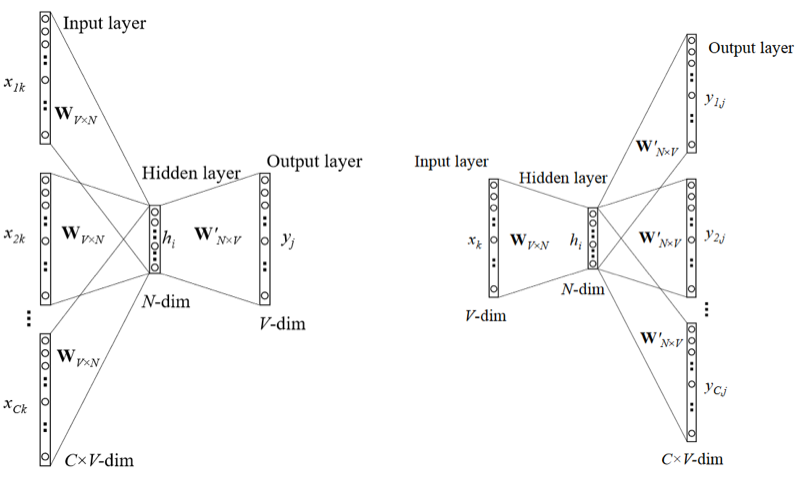
图中那个N-dim vector,是我们需要的值。
Word2vec是一个静态的模型,它试图通过一个足够大的训练数据集,给每一个词分配确定的向量。
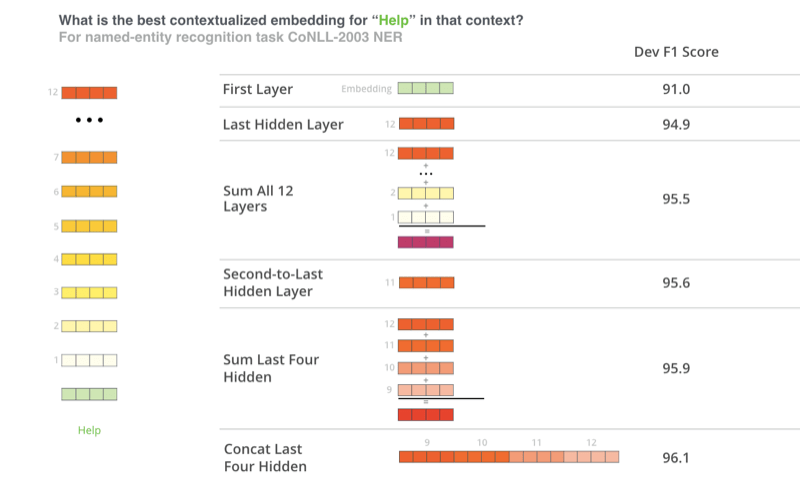
BERT中的embedding模型
随着NLP的发展,产生了动态embedding,词的vector与句子相关,而不只是词本身。比如BERT中使用的Embedding,就与上下文相关。“I want to access my bank account”,和“we went to the river bank”,对于这两个句子中,word2vec给出的bank的向量是固定的,而bert给出的bank的向量是不同的。
BERT并没有限制使用哪些数据作为embedding,选择不同的层的参数作为embedding会产生不同的结果: