Deep Learning(1) - CNN卷积神经网络
CNN是对图像类数据进行处理的最常用方法,主要的思路是通过卷积核对图像的特征进行提取,通过pooling对数据进行降维,然后再通过全链接网络输出。
卷积
卷积在数学上的概念相对复杂,而在图像处理的CNN中,卷积可以简单地理解为:用一个矩阵与另一个矩阵相乘,然后对所有的值求和。
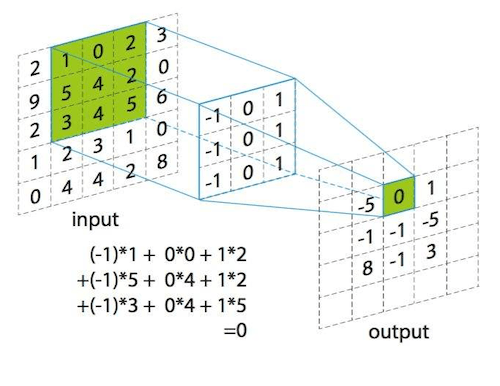
卷积核是一个小的矩阵,比如3x3或5x5,其中一些位置为1,另一些位置为-1。
卷积核其实就是拿着这个矩阵在图片的矩阵上一点点的平移,就像扫地一样。每扫到一处地方就可以进行卷积的运算,计算方法很简单,卷积核矩阵的数字就和扫到的位置的矩阵的数字一一对应相乘然后相加,该值就是卷积核提取的特征。
池化
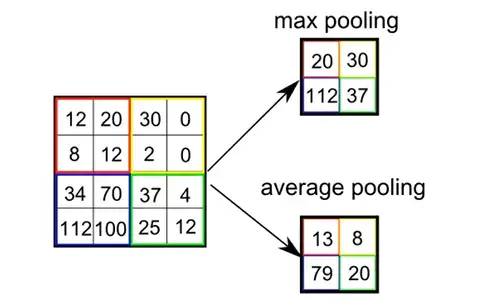
池化是将相邻的几个点转成一个点的方法,这样处理后,图像的维度会大幅度下降:
LeNet-5
有了这几个新的概念,就可以构造出经典的LeNet-5(由Yann LeCun在1998年提出,现在他是Meta的AI负责人)神经网络,这个网络可以有效识别单个的手写数字。

可以看到,这个网络并不复杂,所以也算不上“深度”。前面两个卷积层接池化层,后面两个全连接层后直接输出结果(10个维度的向量,用其中的每一位依次表示0-9的数字)
AlexNet
在AlexNet提出之前,CNN在很多比赛中,成绩并不是最优的。一些经过人的手工精心设计的特征流水线组成的算法,往往成绩更好。AlexNet是第一个比较成功的,基于GPU的CNN算法,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
AlexNet从LeNet-5的基础上向前走了一步,下图左面是LeNet,右面是AlexNet。AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。

在AlexNet中,参数的数量达到了6千万。
GoogleNet
在2014年赢得ImageNet的GoogleNet,将深度学习推向了新的高度,它的网络结构已经真的“深”了。
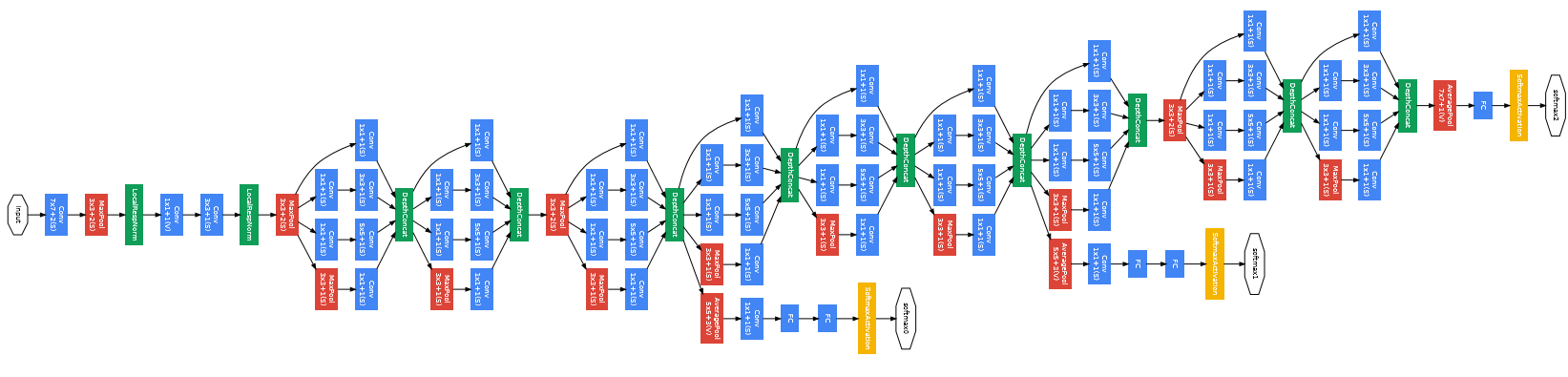
GoogleNet的深度达到了22层,但大幅减少了参数的数量,仅仅大约为5百万个。