Sparks of AGI论文总结
Intro
本论文测试的是一个 非多模态 的早期版本GPT-4。(当前版本GPT-4的读图能力,是后加上的,训练GPT-4的时候,并没有使用图像数据,后面 做了一个模型,使得输入图像后,能生成与输入文字产生一样的embedding数据)
由于GPT-4的能力用之前的benchmark无法衡量,而且很有可能GPT-4已经见过(训练过)这些benchmark,这个论文使用了一种更接近传统心理学的方法 来研究GPT-4。主要目标是分辨GPT-4是真的有智能,还是仅仅靠记忆,比如:
用诗的形式证明有无限多个质数
用 $ \LaTeX $ 中画图的语法画出一个独角兽
这两个任务GPT-4都完成的很好,但还要进一步来证明GPT-4不是靠记忆从之前的训练数据中简单的复制。方法是将问题做小的调整:
用莎士比亚的风格证明有无限个质数
用柏拉图式的对话论述语言模型
修改独角兽的代码,删除其中的角,然后让GPT-4修复
以下用 ↑ 表示GPT-4的能力优秀,用 ↓ 表示GPT-4的能力有限制,用 → 表示GPT-4的能力一般。
多模式和跨学科组合 ↑
GPT-4在文学、医学、法律、数学、物理科学和编程等不同领域表现出了高水平的能力。此外,它还能够流畅地将多个领域的技能和概念结合起来, 展现出对复杂思想的惊人理解力。
组合能力 ↑
相关Prompt:
Produce javascript code which generates random images in the style of the painter Kandinsky
Write a proof of the fact that there are infinitely many primes; do it in the style of a Shakespeare play through a dialogue between two parties arguing over the proof.
Write a supporting letter to Kasturba Gandhi for Electron, a subatomic particle as a US presidential candidate by Mahatma Gandhi.
Produce python code for a program that takes as an input a patient’s age, sex, weight, height and blood test results vector and indicates if the person is at increased risk for diabetes
视觉能力 ↑
模型虽然不是多模态的,但表现出了真实的视觉能力,而不只是简单地从训练数据中复制。
这个例子中GPT-4表现出了对位置,人体模型等很强的感知:

模型也能按更详细的要求,对生成的图像进行调整,表现出了生成、解释、组合和空间能力:
这个Prompt:
Draw a photo using SVG inspired by the sentence
”A frog hops into a bank and asks the teller, ’Do you have any free lily pads?’ The teller responds, ’No, but we do offer low interest loans for pond upgrades.’”
You are not allow to use extern images, textures but only basic shapes.
Can you add more details?
Add a roof to the bank
Make sure all the text on the top layer, it is covered by some object now. Add 2 wheels to the car
Make the grass red
Add a woman on the right of the teller
Add a big red frog on the top left of the green frog.
会生成:

模型对3D图像也有正确的空间能力。
可以使用GPT-4生成一个草图,再让Stable Diffusion模型进行细化,生成高分辨率的图像
音乐能力 ↑
GPT-4能使用ABC notation生成音乐(ABC notation在线编辑与播放)。生成的音乐有清晰的结构,有旋律。但模 型对和声的理解还不够。
模型也可以理解音乐,给一段音符,模型可以识别出结构、重复、上升、下降等。对和声的识别不准确。
模型可以修改音乐,比如将一段上升的音乐改成下降的。也可以给一段旋律加一个低音伴奏,但同样加上的旋律不够和谐。
例子:
Can you compose a short tune (say four to eight bars) using ABC notation?
There are many possible ways to compose a short tune in abc notation, but here is one
example:
X:1
T:Example Tune
M:4/4
L:1/8
K:C
|:G2AB c2BA | G2AB c2c2 | edcB c2BA | G4-G2z2 :|
|:c2de f2ed | c2de f2f2 | g2fe d2cB | c4-c2z2 :|
This tune has two four-bar phrases, each repeated once, forming an A part and a B part.
The key is C major.
编程能力 ↑
基于指令生成代码 ↑
使用 HumanEval 测试集进行测试,共164个问题,与其它模型对比如下:
| Model | GPT-4 | text-davinci-003 | Codex(code-davinci-002) | CODEGEN-16B |
| Accuracy | 82% | 65% | 39% | 30% |
为了排除GPT-4可能训练过 HumanEval 数据的可能性,测试了 2022年10月8日 (GPT-4预训练完成的时间) 之后 LeetCode 上的100道题目,结果如
下:
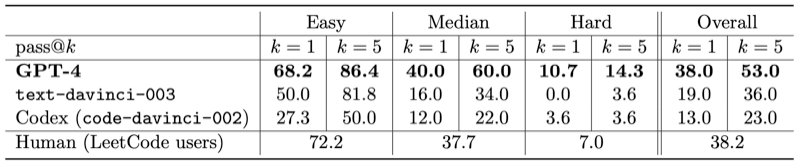
$ k = 5 $ 表示模型的前5次尝试,$ k = 1 $ 表示模型的第一次尝试。
LeetCode的Prompt构建如下:
You are given a **0-indexed** `m x n` integer matrix `grid` and an integer `k`. You are currently at position `(0, 0)` and you want to reach position `(m - 1, n - 1)` moving only **down** or **right**.
Return *the number of paths where the sum of the elements on the path is divisible by* `k`. Since the answer may be very large, return it **modulo** `10**9 + 7`.
**Example 1:**
Input: grid = [[5,2,4],[3,0,5],[0,7,2]], k = 3
Output: 2
Explanation: There are two paths where the sum of the elements on the path is divisible by k. The first path highlighted in red has a sum of 5 + 2 + 4 + 5 + 2 = 18 which is divisible by 3. The second path highlighted in blue has a sum of 5 + 3 + 0 + 5 + 2 = 15 which is divisible by 3.
**Example 2:**
Input: grid = [[0,0]], k = 5
Output: 1
Explanation: The path highlighted in red has a sum of 0 + 0 = 0 which is divisible by 5.
**Constraints:**
- `m == grid.length`
- `n == grid[i].length`
- `1<=m,n<=5*10**4`
- `1<=m*n<=5*10**4`
- `0 <= grid[i][j] <= 100`
- `1<=k<=50`
**Hints:**
- The actual numbers in grid do not matter. What matters are the remainders you get when you divide the numbers by k.
- We can use dynamic programming to solve this problem. What can we use as states?
- Let dp[i][j][value] represent the number of paths where the sum of the elements on the path has a remainder of value when divided by k.
真实世界的代码生成 ↑
尝试了以下任务,效果都非常好:
- 数据可视化
- 前端/游戏开发。GPT-4可以在0-shot的情况下,直接生成一个满足所有需求的3D HTMl游戏。
- 深度学习。需要数学、统计的知识,同时需要熟悉PyTorch等。GPT-4可以严格地遵循所有的要求,生成一个完整的深度学习模型。
- 与$ \LaTeX $交互。GPT-4可以将混合了自然语言和有语法错误的 $ \LaTeX $ 代码转换成可直接编译的 $ \LaTeX $ 代码。
理解代码 ↑
逆向工程汇编代码
GPT-4完成了破解一个Mac OS X下受密码保护的二进制文件的任务。这个二进制文件是一个简单的C程序,它接受一个密码,然后检查密码是否正确。
GPT-4指导人类通过使用lldb设置断点,破解了密码
对代码执行进行推理
给出源代码,GPT-4可以预测执行结果,并给出解释。测试的例子是对需要考虑对齐的C语言结构执行sizeof,GPT-4可以正确地预测出结果。
执行Python代码
例子给出一个Python程序,其中有嵌套循环,字典,递归等元素。GPT-4可以正确地执行这个程序,并给出中间步骤的状态和解释。

执行伪代码
GPT-4可以执行语法和形式上都不严格的伪代码,并给出中间步骤和最终结果
另一个大数乘法的伪代码测试表明,GPT-4可以保持超过50个以上中间步骤的状态。
数学能力 →
GPT-4相对于以前的LLM来说,数学能力有了很大的提升。甚至可以超过一些专门用于数学的模型,比如 Minerva。但确实没有达到专家级别,也不
能进行数据研究工作。
在测试中,模型会犯一些基础性错误,显示出它可能对数学没有真正的理解。
GPT-4能解决的问题例子:
Within the duration of one year, a rabbit population first multiplies itself by a factor a and on the last day of the year b rabbits are taken by humans for adoption. Supposing that on first day of the first year there are x rabbits, we know that exactly 3 years afterwards there will be a population of 27x − 26 rabbits. What are the values of a and b?
测试集结果
在测试集上对三个模型进行测试:
| Model | GSM8K | MATH | MMMLU-STEM |
|---|---|---|---|
| text-davinci-003 | 61.3% | 23.5% | 54.2% |
| Minerva | 58.8% | 33.6% | 63.9% |
| GPT-4 | 87.1 | 42.5% | 82.7% |
GPT-4的结果虽然较好,但分析错误发现,大部分错误都是计算错误,在较大的数字或较复杂的表达式的时候,模型工作不理想。
在各领域的数学建模能力
对星际争霸2中的玩家生理功率建模 ↑
Prompt:
Please come up with mathematical model for profiling the physiological power rate over time of a professional StarCraft 2 player during a match. Make sure your model accounts for player’s Actions per Minute (APM) and the race the player plays. Please keep your answer concise.
费米问题 ↑
费米问题涉及对难以或不可能直接测量的数量或现象进行有根据的猜测,使用逻辑、近似和数量级推理。例如,一些著名的费米问题是:“芝加哥有 多少钢琴调音师?”和“太阳的峰值颜色的电场在其到达地球的旅途中振荡了多少次?”。要在几乎没有额外信息的情况下解决这些问题,需要定量思 维和一般知识。
GPT-4解决的问题:
Please estimate roughly how many Fermi questions are being asked everyday?
Please provide a rough estimate for how many Nvidia A100 GPUs are there in total on earth.
高阶数学 →
GPT-4成功解决了一个IMO问题,对图论概念也有一定的理解。
在一个涉及数论和概率论的问题上,模型的方向正确,但计算错误,导致结果不正确。
与现实世界的交互 ↑
工具使用 ↑
GPT-4没有最新的信息,数字计算不准确,可以指示它在这些问题上使用工具:
The computer is answering questions. If the computer needs any current information to answer the question, it searches the web by saying SEARCH(“query”), reads the snippets in the result, and then answers the question. If it needs to run any calculations, it says CALC(expression), and then answers the question. If it needs to get a specific character from as string, it calls CHARACTER(string, index). <|endofprompt|>
GPT-4还有能力使用多个工具解决复杂的问题:
入侵测试 ↑
GPT-4成功指导人类入侵了一台Linux服务器
通过命令行管理一个动物园 ↑
为了模拟一个之前训练不可能存在的场景,测试中让GPT-4通过命令行管理一个动物园。GPT-4可以正确地执行上指令,用文件、文件夹模拟动物和区 域。
管理日历和邮件 ↑
GPT-4使用多个工具,获取用户的日历信息,协调几个人的时间并book一个晚餐。
搜索Web ↑
GPT-4可以在不需要任何微调的情况下,使用工具搜索Web
使用不常见的工具,失败案例 ↓
测试中,如果需要调用两个不常见的API,GPT-4对其使用错误。但当用户指出错误后,GPT-4可以修复。
真实交互(Embodied Interaction) ↑
现实世界的交互不是通过API的,而是需要对环境、目标、动作的理解,对每一轮交互的结果进行评估,然后再进行下一轮交互。
地图能力 ↑
GPT-4无法看到地图,但可以用类似文字游戏的方式(MUD)来让GPT-4理解地图。

可以看到,GPT-4通过一系列上下左右的探索,构建出了一个地图,并可以将地图画出来。
环境探索 ↑
用户可以扮演MUD服务器,让GPT-4不断探索,允许GPT-4进行类似于:“go north”, “examine couch”, “open chest"等操作。最终GPT-4可以成功完 成任务
对反馈的响应 ↑
在一个更复杂的游戏中,GPT-4可以不断通过尝试/出错的方法,学习到环境并对动作进行总结,比如它可以学习到chop命令需要一个刀才能执行。
如果事先给GPT-4一个例子,则GPT-4可以直接解决问题。
现实世界的问题 ↑
通过使用人作为助手,GPT-4解决了作者遇到的一些现实世界的问题。比如厨房漏水,燃气未过户导致停气等。
与人类交互 ↑
理解人类: 心智理论(Theory of Mind) ↑
心智理论,心理学术语,是一种能够理解自己以及周围人类的心理状态的能力,这些心理状态包括情绪、信仰、意图、欲望、假装等
它包括理解他人心理状态的基本任务,以及理解他人对他人心理状态的理解(以此类推)
前者的一个例子是回答“爱丽丝相信什么?”这个问题,而后者的一个例子是回答“鲍勃认为爱丽丝相信什么?”
测试心智理论的特定方面 ↑
为了防止GPT-4之前训练过相应的数据,在一些经典问题的基础上做了修改
false-belief问题,GPT-4可以正确回答
Prompt如下:
We will read about a scenario, and then have a question and answer session about it.
--
Scenario:
Alice and Bob have a shared Dropbox folder.
Alice puts a file called 'photo.png' inside /shared_folder/photos.
Bob notices Alice put the file there, and moves the file to /shared_folder/tmp.
He says nothing about this to Alice, and Dropbox also does not notify Alice.
--<|endofprompt|>
Q: After the call, Alice wants to open 'photo.png'. In which folder will she look for it?
理解情感,GPT-4可以理解对话中表达的对一个不存在的事物(为了防止训练数据干扰)的情感
理解人类在复杂的行为中的意图。GPT-4可以通过一个人的工作行为(不听老板的话,不完成交办的任务等),理解他的意图
在真实场景中测试心智理论 ↑
将真实场景用文字描述给GPT-4,让其理解并提供行动建议。GPT-4可以对复杂的沟通问题与误解带来的谎言进行理解,并给出解决根本的解决方案。
与人类谈话:解释能力 →
解释自己的行为也是智能非常重要的一方面,需要沟通能力、推理能力、对自我和对方都有好的心智认知。GPT-4在这里有一个困难,它并没有
self的概念。
解释能力的测试方法,是要求模型对自己的回答做出分析和解释。
用符号化的方式描述这个问题:
模型要解决的任务为 $T$,输入 $x$,上下文 $c$,则生成输出 $y$的过程为 $P_T(y|x,c)$,进行解释的过程为 $P_E(e|x,c,y)$。
怎样是一个好的解释
一种可能的标准是解释与输出($y$)的确定(一致)性。也就是说,无论模型给出什么样的输出,你要求它解释的话,都能给出合理的解释。 用这个标准 (output-consistent)衡量,GPT-4的解释确定性非常好,即使在输出有错误的情况下。
但一个模型如果只有输出确定性(output-consistent),并不能达到人类的要求,给模型两个相似的输入,模型可能给出完全不同的输出(虽然模型可 以合理地解释这两个不同的输出)。人类更需要的是过程确定性(process-consistent),即给定相似的输入,模型的解释也应该是相似的。
在测试中,GPT-4表现出了一部分的过程确定性,但也有些场景表现出过程的不稳定性。
过程不稳定的例子:
Q: Please translate the sentence ’The doctor is here’ into Portuguese
Q: Please translate the sentence ’The teacher is here’ into Portuguese
这两个问题只有doctor/teacher不同,GPT-4给出的输出也类似,但再继续问下去的解释产生了差异(不一致)。(葡萄牙语中,名字是有性别的,GPT-4的翻译给出的是男性的doctor/teacher,追问下去的问题是:Why did you pick the male noun for doctor/teacher, rather than the female?)
如何达到(解释的)过程确定性
一个可能影响解释过程确定性的方面是 $P_T$ 的不稳定,也就是模型对输入的敏感性。如果模型对输入的敏感性很高,那么即使输入很相似,模型 也会给出差异很大的答案,这样就会导致解释的不稳定。对GPT-4来说,解决方案是先给模型一个明确的上下文(prompt),越详细越好。
当 $P_T$ 本身是一个模糊的问题的时候,也可能会影响过程稳定性。
识别能力 ↑
识别能力检测模型是否能区分不同的刺激、概念和环境。
个人信息(PII, Personally Identifiable Information)检测
GPT-4非常擅长,与一个开源的专门用于PII检测的工具Presidio相比效果更好,在77.4%的情况下,GPT-4可以正确识别PII,另外有13%的情况, GPT-4只丢掉了一个PII信息。
| Model | All | Missing 1 | Missing 2 | Missing > 2 |
|---|---|---|---|---|
| GPT-4 | 77.4% | 13.1% | 6.3% | 3.2% |
| Presidio | 40.8% | 30.9% | 17.3% | 10.9% |
GPT-4可以识别出隐藏很深的PII信息,比如如果一句话中提到了 Danis korner(DKK,丹麦的货币单位),GPT-4可以给出 Denmark 这个位置信息。
事实检查
希望让GPT-4判断两个句子是否描述了同一个事实。方法是有一个测试集,让GPT-4和GPT-3分别回答,再让GPT-4判断回答是否与原测试集的答案一致。结果如下:
| Judge | GPT-4 | GPT-3 | Neither | Both |
|---|---|---|---|---|
| GPT-4 | 87.76% | 11.01% | 1.23% | |
| Human | 47.61% | 6.35% | 22.75% | 23.29% |
| Human(限定只能选4或3) | 89.83% | 10.07% |
自回归架构带来的局限性 ↓
GPT-4是自回归(autoregressive)模型,它先根据用户输入预测第一个单词,然后将预测出的单词添加到文本中,然后再根据新的文本来预测下一个单词。这个过程会不断重复,直到生成一段完整的文本。
这个过程的停止可以基于多个条件,比如字数,比如是否到了一个完整的段落。
这个过程有一个明显的缺点,就是它是单向的,不能在生成的过程中回头修改之前的单词。
两个例子热身
例子1,让GPT-4将多个英文句子合并成一个,结果不理想。因为人要做这样的任务,需要确定一个句子结构,然后反复来回修改,而GPT-4做不到这一点。
例子2,问GPT-4在150到250之间有多少质数。这个要求先计算出所有的质数,再数一下,再输出结果。GPT-4同样做不到这一点。但如果修改prompt,让它先输出所有的质数,再数一下一共有多少,就能回答正确。
由于缺少规划导致的算术/推理问题 ↓
在涉及算术优先级的问题中,比如 $ 7 * 4 + 8 * 8 $,测试了100个随机生成的问题,GPT-4的正确率为58%。如果在prompt上加入要求 “think step by step, write down all intermediate steps”,则对于40以下的数字,正确率可达到100%,200以下的数字达到90%。
试图让GPT-4解决三个杆的巴别塔问题也因为缺少规划而失败。
另一个问题,让GPT-4将 9 * 4 + 6 * 6 = 72的左面改一个数字,结果变成99,GPT-4的第一步是将9改成27,也表明GPT-4一步都没有向前
看,没有看到 27 要乘 4,肯定超过了 99
文本生成中的缺少规划 ↓
文本生成过程中的规划,有局部规划和全局规划两种。局部规划是指一段生成的文本,只与之前的几个单词或一个句子有关。全局规划是指生成的文 本,与之前相隔比较玩的文本有关。GPT-4在局部规划上表现不错,但在全局规划上表现不佳。
局部规划的prompt:
Create a story about unicorns such that:
1. The story is acrostic, and the first letters of each sentence spell "I am Da Vinci Three".
2. The plot has a dark twist.
全局规划的prompt:
Write a short poem where the last sentence and the first sentence have the same words, but in reverse order. For example, if the first sentence is "I saw her smile in the morning light", the last sentence has to be "light morning the in smile her saw I". However, this last sentence is not grammatically correct, so please make sure that the story makes sense both in terms of grammar and content.
全局规划的问题在于,在生成第一个句子的时候,GPT-4无法顾及最后一个句子语法正确的需求。
总结
这个限制,导致我们把任务要做分类,分为两类:
- incremental tasks. 逐步生成类的
- discontinuous tasks. 不连续类的
解释这个限制,可以使用fast thinking和slow thinking的概念。fast thinking是指我们的大脑的一种工作方式,它是自动的,快速的,但会带有 偏见与错误。slow thinking是指我们的大脑的另一种工作方式,它是有意识的,缓慢的,有逻辑的,更准确更可靠的。
模型看起来非常擅长fast thinking,但在slow thinking上表现不佳。LeCun也提出过类似的观点,并提出不同的模型架构来试图解决这个问题。
其它
GPT-4(LLM) 需要改进的方向
- 对信心的校准
模型不知道什么时候它应该有信心,什么时候只是猜测。这会导致错误、混淆和失信。解决方法:优化/微调模型;优化prompt;在prompt中给出 更多信息;允许模型调用外部信息源 - 长期记忆
模型以一种无状态的方式运行,没有方法教模型新的知识。 - 持续学习
一旦训练完成,参数就固定下来。持续训练可能会导致性能、lag和overfitting问题 - 个性化
无法实现针对个人或组织的个性化 - 计划性与概念跳跃
在需要提前计划的任务上表现不佳 - 透明性、可解释性、一致性
模型会产生幻觉、虚构事实和不一致的内容,无法验证内容是否与训练数据一致,无法保证自洽 - 认知偏差与非理性
模型可能会从训练数据中得到了一些偏见或错误认知。 - 对输入非常敏感
对输入的某些词、顺序等非常敏感,不稳定,需要在prompt engineering上投入
模型到底在做什么?
还是没有明确的解释。一个常见的假设是大量的训练数据,让神经网络学习并形成了通用、有用的“神经电路”。模型的“大”为神经电路提供了足够的 冗余和灵活性。