LoRA Intro
LoRA是Low-Rank Adaptation的缩写,出自论文Low-Rank Adaptation of Large Language Models
LoRA是一种用于大语言模型的低秩(Rank)fine tune方法,它可以在不增加模型参数的情况下,显著提高模型的泛化能力。
其主要思路可以用下图来说明:
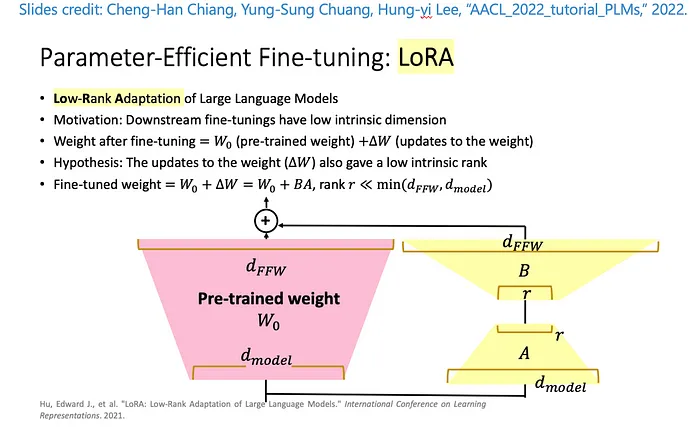
假设我们要fine tune的一个参数矩阵 $W_0$,它的维度是 $d_{model} \times d_{FFW}$,在LoRA fine tuning的过程中,$W_0$是不变的,我们的目标是计算出一个 $\Delta_W$,纬度也是 $d_{model} \times d_{FFW}$,这样 $W_0 + \Delta_W$ 就是我们最终的参数矩阵。
LoRA在这里引入了一个参数r(Rank),将$\Delta_W$拆成了两个矩阵 $A \times B$,其中 $A$ 的维度是 $d_{model} \times r$,$B$ 的维度是 $r \times d_{FFW}$。而r的值,论文认为2~4之间的效果都很好。
这样,LoRA就将需要fine tune的参数数量,从 $d_{model} \times d_{FFW}$ 降低到了 $d_{model} \times r + r \times d_{FFW}$
在实际的测试中,LoRA的效果非常好,其效果不亚于(甚至超过)在原参数上fine tune的效果。
LoRA另一个好处是,fine tune完成后,可以将 $\Delta_W$加回到 $W_0$上,这样就可以恢复到原来的参数规模,在推理阶段不会带来任何的额外计算量。