Text-to-SQL by LLM Benchmark
总结自论文 https://arxiv.org/pdf/2308.15363.pdf
Intro
影响Text-to-SQL主要有以下三个方面:
- 问题表达 (question representation)
- Prompt中的例子 (in-context learning)
- fine-tuning
问题表达
有以下几种方法:
- Basic Prompt($BS_P$)
Table continents, columns = [ContId, Continent]
Table countries, columns = [CountryId, CountryName, Continent]
Q: How many continents are there?
A: SELECT
- Text Representation Prompt ($TR_P$)
Given the following database schema:
continents: ContId, Continent
countries: CountryId, CountryName, Continent
Answer the following: How many continents are there?
SELECT
- OpenAI Demostration Prompt ($OD_P$)
OpenAI给的例子中的Prompt
### Complete sqlite SQL query only and with no explanation
### SQLite SQL tables, with their properties:
#
# continents (ContId, Continent)
# countries (CountryId, CountryName, Continent)
#
### How many continents are there?
SELECT
- Code Representation Prompt ($CR_P$)
能表达主键、外键
/* Given the following database schema: */
CREATE TABLE continents (
ContId int primary key,
Continent text,
foreign key(ContId) references countries(Continent)
);
CREATE TABLE countries (
CountryId int primary key,
CountryName text,
Continent int,
foreign key(Continent) references continents(ContId)
);
/* Answer the following: How many continents are there? */
SELECT
- Alpaca SFT Prompt ($AS_P$)
是为fine-tuning设计的Prompt
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Write a sql to answer the question "How many continents are there?"
### Input:
continents (ContId, Continent)
countries (CountryId, CountryName, Continent)
### Response:
SELECT
问题表达对结果的影响
- 测试1,使用所有问题表达的原始格式
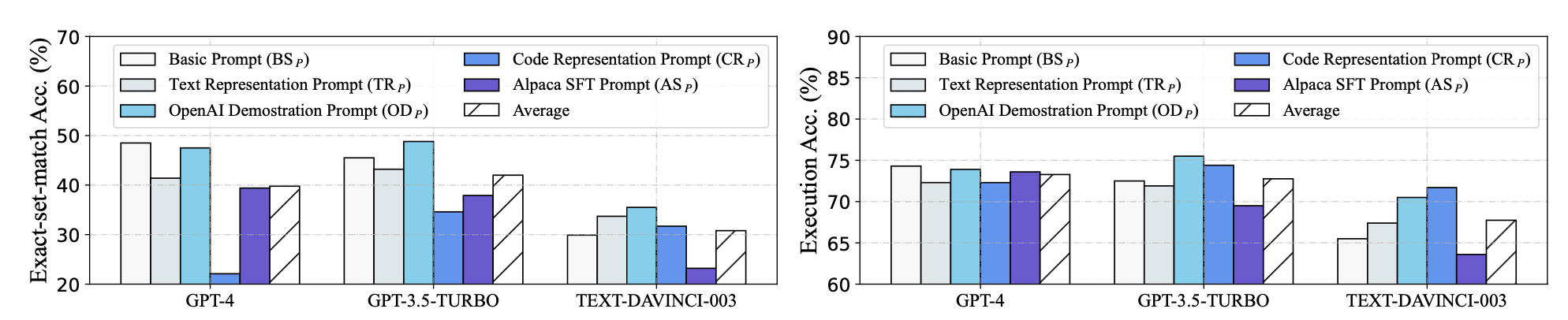
$OD_P$ 在所有模型上都不错,GPT-3.5上表现最好。GPT-4反而在使用 $BS_P$ 时更好,表明更强大的模型能通过文本理解更复杂的设计。
- 测试2,补充外键信息
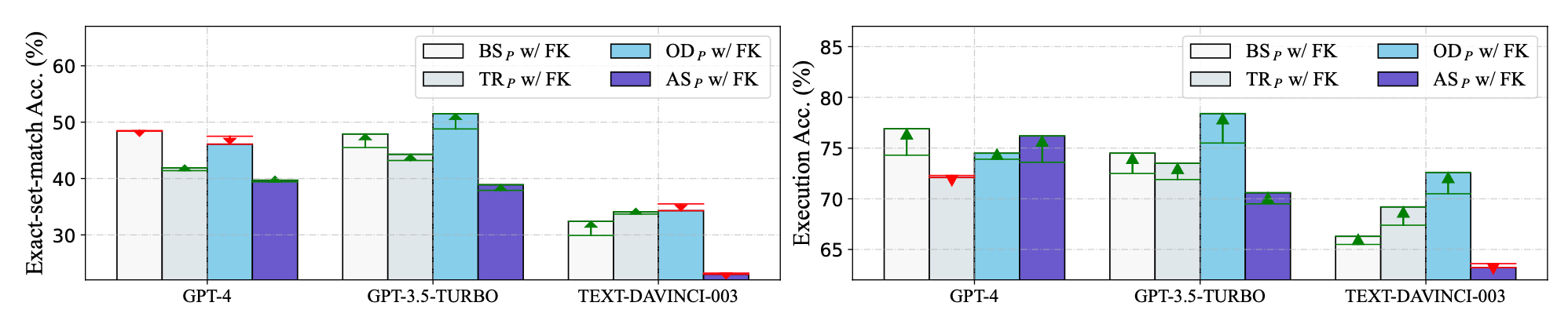
在 $BS_P, OD_P, TR_P, AS_P$ 中,加入外键信息后($CR_P$中原本就有)的测试数据,绿色表示性能有改善,红色表示有下降。
- 测试3,加入
with no explanation
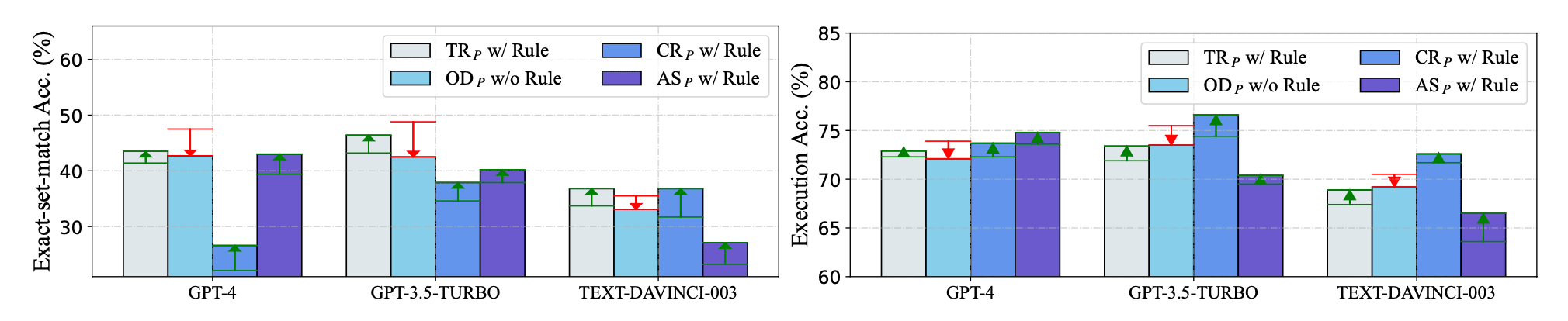
$OD_P$中有一个with no explanation,这里测试其它几个加入这句话后的变化
In-Context Learning
在Prompt中加入例子,有以下两方面要考虑
1. 例子选择
- Random
从一个库中随机挑选
- Question Similarty Selection ($QTS_S$)
基于问题的相似性,对问题事先做embedding
- Masked Question Similarty Selection ($MQS_S$)
对于通用的Text-to-SQL场景,先将表名、字段名和值做替换后再进行embedding,做相似搜索
- Query Similarty Selection ($QRS_S$)
基于query的相似性:先用一个模型,用0-shot的方式生成一个query(SQL),再对query进行embedding的相似搜索
2. 例子组织
- Full Information Organization ($FI_O$)
在每个例子中,加入数据库的schema
/* Given the following database schema: */
${DATABASE_SCHEMA}
/* Answer the following: How many authors are there? */
SELECT count (*) FROM authors
/* Given the following database schema: */
${ DATABASE_SCHEMA}
* Answer the following: How many farms are there? */
SELECT count (*) FROM farm
${TARGET_QUESTION}
- SQL Only Organization ($SO_O$)
/* Some SQL examples are provided based on similar problems: */
SELECT count (*) FROM authors
SELECT count (*) FROM farm
${TARGET_QUESTION}
DAIL方法
例子选择 ($DAIL_S$)
将例子中和目标问题中所有的domain相关术语mask掉,然后同时对Q和预生成的SQL进行向量搜索,SQL搜索的结果要满足一个设定的阈值,按Q搜索的结果排序。
例子组织 ($DAIL_O$)
结合 $FI_O$和$SO_O$
/* Some example questions and corresponding SQL queries are provided based on similar problems: */
/* Answer the following: How many authors are there? */
SELECT count (*) FROM authors
/* Answer the following: How many farms are there?. */
SELECT count (*) FROM farm
${TARGET_QUESTION}
测试结果
使用 $CR_P$ 作为问题表达,使用4096的上下文长度,留200个token用于生成数据
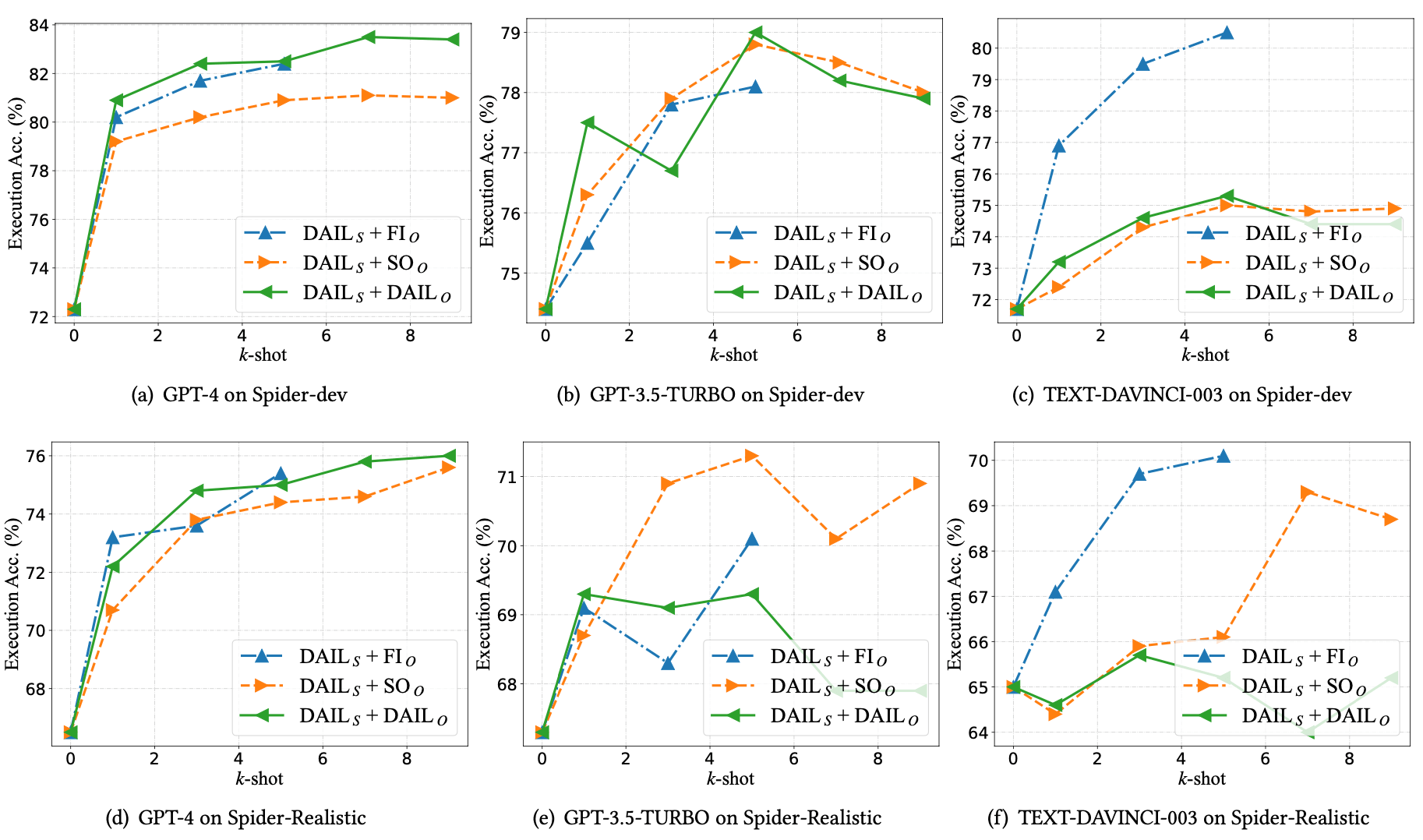
- GPT-4 对于增加例子响应最好(例子越多结果越准确),说明有比较强的上下文学习能力
- GPT-3.5和Text-Davinci-003,增加例子反而可能结果会变差
- GPT-3.5相对于0-shot的结果,改善最小
- Text-Davinci-003最喜欢 $FI_O$
- 综合数据,GPT-4 + $DAIL_O$ + $DAIL_S$ 结果最好
Fine-tuning
对开源模型做fine-tuning后进行了测试,有以下几个结论:
- fine-tuning对0-shot非常有效,测试结果比GPT-4和GPT-3.5稍弱
- fine-tuning后对few-shot结果非常差,有可能是在fine tuning的过程中,对0-shot产生了over fitting